How We Used AI-Native Engineering to Cut Development Time by 30%
AI, AI Development, Experts Voice, product & platform
Read more

Most business leaders agree that big data has become crucial to developing a viable business model in today’s marketplace. But big data alone isn’t enough. Being able to effectively analyze and act on a massive store of data is almost more important than collecting it in the first place. Data scientists are the ones who sort through that data, discovering actionable trends and insights that can take your business strategies to the next level.
Making big data actionable is a complex process that involves communication between data scientists (the ones who analyze the data) and engineers (the ones tasked with putting their ideas and insights into production). This divide is where problems commonly arise. Getting the most value out of your data means making sure data scientists and engineers can communicate and work together effectively. With that in mind, here are a few tips to ensure a smoother, more coordinated development process.
A shared language and terminology are essential for strong communication and collaboration. Cross-training is one of the simplest methods for achieving that shared language and breaking down the divide between data scientists and engineers. For data scientists, this might mean learning the basics of production languages. For engineers, it might mean studying the fundamentals of data analysis.
Assigning employees a partner from the other division can help facilitate the learning process, while also helping both departments recognize what changes they could make to help the other team and make their work easier. For instance, engineers might communicate to data scientists that a more organized code would expedite the production process.
As we’ve seen, communication is key. One of the best ways to facilitate communication is by emphasizing the importance of clean code. For data scientists, analyzing big data can sometimes be a messy, experimental process, resulting in preliminary code that can be difficult to understand for engineers. If engineers begin to work from the substandard code, their model software will likely run into problems, including instability and overall efficiency.
Implementing standardization protocols that consider security parameters, data access patterns, and other factors can keep both sides of the development team happy and expedite the development process. If your data scientists can consistently produce code that performs well within your engineers’ development framework without sacrificing any of the functionality the data scientists need to continue their work, the entire process will run more smoothly.
Once you’ve established a system for consistently producing clean code, it’s time to productize it. Think of this approach as a way of segmenting features (or independent variables in the data), curating them, and storing them in a centralized location. The intent is better information sharing. Data scientists can retrieve these features when they’re working on a project, and they can be confident that the features are reliable and tested. This approach also produces analysis benefits. A features store is essentially a data management layer that uses machine-learning algorithms to analyze raw data and filter it into easily recognizable features.
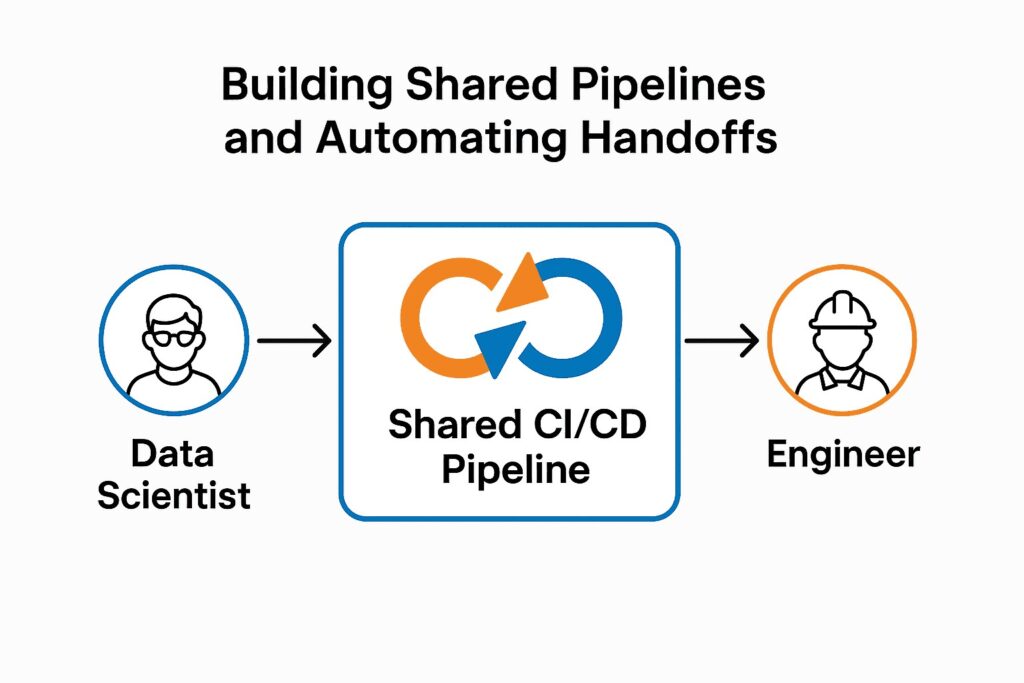
Once your teams speak the same language and your data is structured for reuse, the next step is to operationalize that collaboration through shared pipelines. Instead of treating data science and engineering as two separate workflows, align them under a unified CI/CD (Continuous Integration / Continuous Deployment) framework tailored for machine learning and analytics.
This means:
With shared pipelines in place, data scientists can push models that engineers can immediately implement — without custom translation work. It also makes experimentation safer and faster: if something breaks, you know where, why, and how to fix it.
Automation doesn't just save time. It builds trust. And in a data-driven environment, trust between teams is what turns prototypes into products.
Big data refers to large and complex data sets that traditional data processing tools cannot handle efficiently. It's important because it enables businesses to uncover patterns, trends, and insights that support better decision-making and innovation.
Data scientists focus on analyzing big data to uncover insights, while engineers are responsible for building and maintaining the systems that make those insights usable in production environments.
Without strong collaboration, insights generated by data scientists may never make it into production, and engineers may lack the context to build optimal solutions. Bridging this gap ensures that big data becomes actionable.
Tools like Databricks, MLflow, Airflow, and feature store platforms such as Feast support collaboration by standardizing workflows, sharing artifacts, and maintaining traceability across teams.