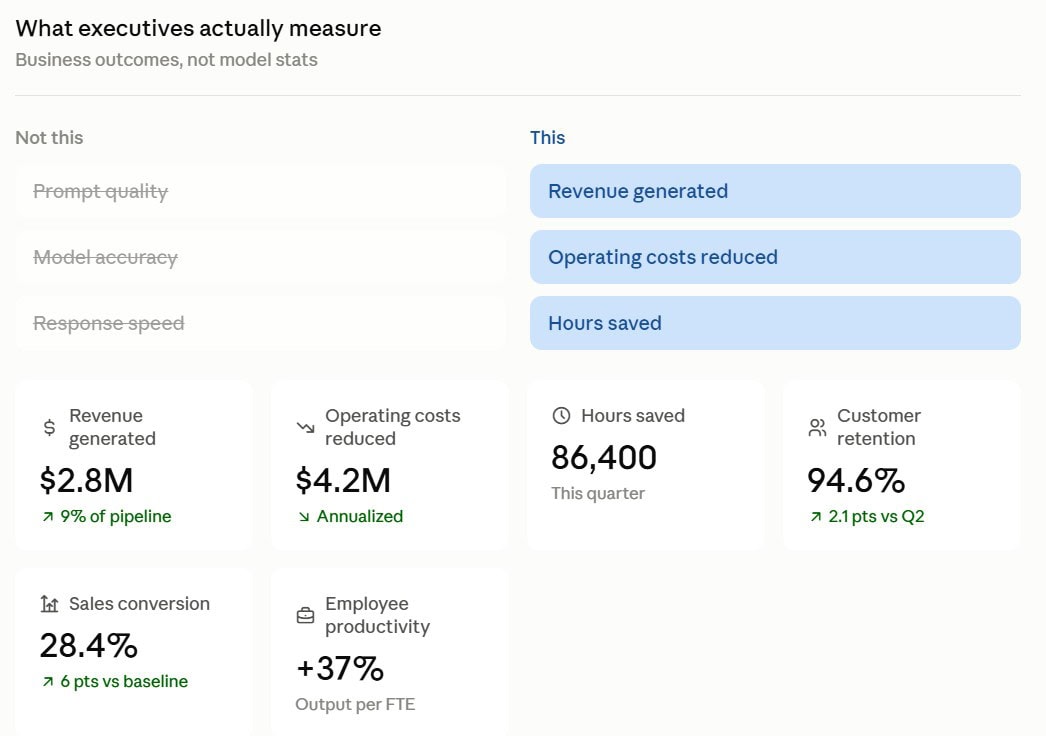
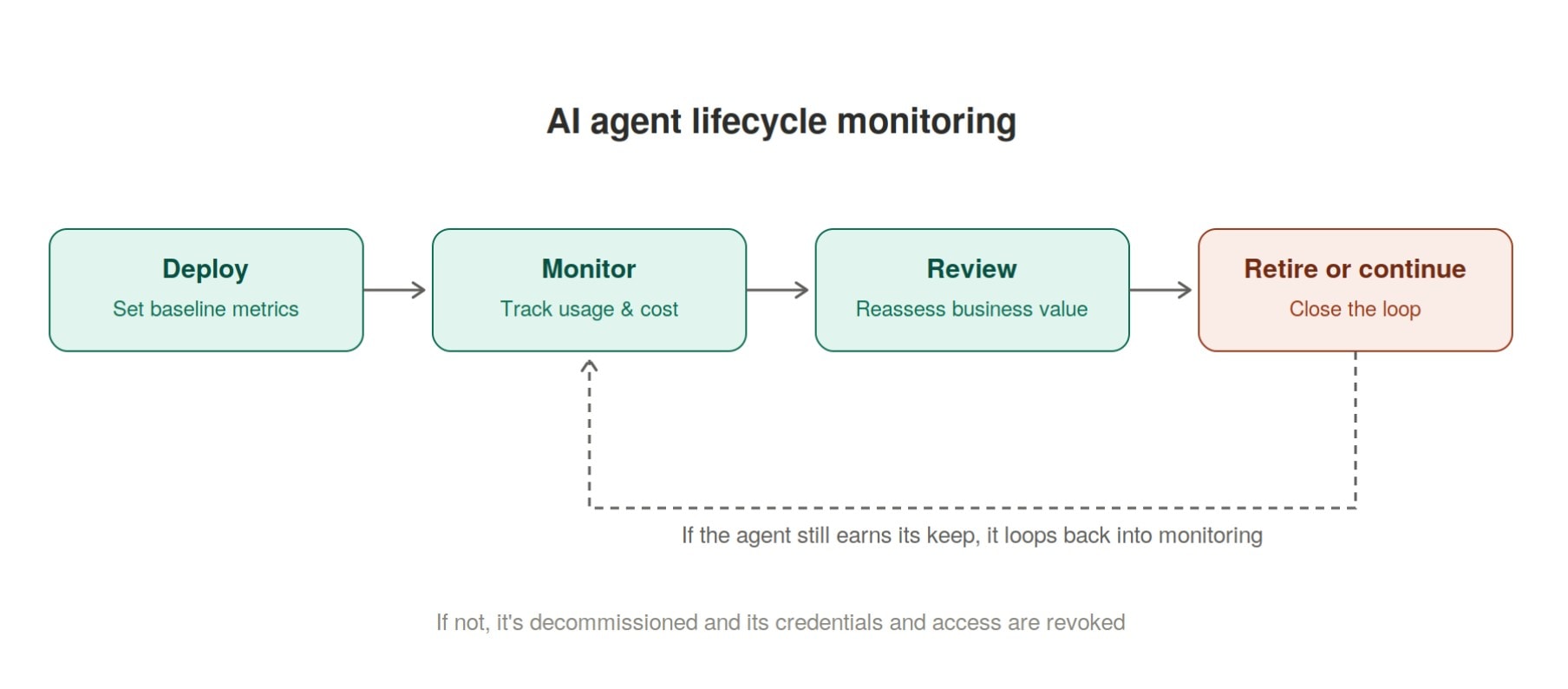
Modern architecture demands a tight, continuous loop between raw data ingestion and multimodal AI execution. Yet, enterprise data teams often spend millions standing up a pristine Databricks environment, only to realize the business operators refuse to use it. The failure mode is painfully consistent across industries.
CTOs recognize the cycle all too well. It begins with months of discovery and exhaustive requirements documents. This is followed by a handoff to a delivery team that doesn't fully grasp the underlying business domain.
The result is a platform that is technically "done" but structurally broken for how the business actually works. The problem is rarely the technology stack itself. The problem is the delivery model.
The traditional IT services industry relies on two primary models, and both fail under the weight of complex data engineering. The first is standard consulting, which treats software delivery like building a house. You finalize the blueprint, hand it to the contractors, and wait six months for the keys.
The second is staff augmentation. Here, you simply rent capacity, asking an agency for five Data Developers to fill empty seats. There is no shared context and zero accountability for the final business outcome.
Here is exactly where these models diverge when applied to data modernization:
| Delivery Model | Execution Style | Domain Knowledge | Business Accountability |
|---|---|---|---|
| Traditional Consulting | Spec-driven, fixed blueprint | Low (handoff model) | Delivered to spec (technical output) |
| Staff Augmentation | Body-shop, rented capacity | Low (isolated tickets) | None (client manages the outcome) |
| Forward Deployed (FDE) | Evolutionary, adaptive | High (embedded with operators) | Total (owns the business outcome) |
Both legacy models fail because data behaves as an evolving ecosystem rather than a static asset. You cannot perfectly blueprint a data pipeline before you actually interrogate the data in production. When anomalies appear, a traditional delivery team points to the frozen spec, files a change request, and halts momentum.
Forward Deployed Engineering (FDE) offers a different mechanism entirely. We place senior engineers and data architects directly into the client’s operational context. They sit next to the domain experts, completely owning the problem end-to-end rather than blindly executing a rigid statement of work.
The term originally gained traction in product companies pushing complex platforms into rigid enterprise environments. At Opinov8, we have adapted the FDE model specifically for advanced enterprise data services.
"You cannot blueprint a data modernization project the way you blueprint a standard web application. Data is inherently messy, legacy business logic is almost always undocumented, and operational needs pivot rapidly. When you hand a rigid spec to an isolated delivery team, you guarantee friction. To build a data platform that actually drives customer engagement and business value, the engineers have to sit in the trenches with the operators."
Sergii Gotovkin, Head of Digital Solutions - Customer Engagement at Opinov8
The shift requires moving away from measuring outputs to optimizing for system-wide intelligence. Instead of saying, "build this exact pipeline," our FDEs operate under directives like, "our transaction classification is too slow to feed the agentic workflow — fix it."
Data modernization is fundamentally an exploratory process. You simply do not know what the data will allow you to build until you are actively shaping it. Legacy schemas hold hidden technical debt, and business logic is often buried in undocumented SQL scripts.
Requirements must emerge from interacting with the data, not from a theoretical kickoff workshop. Whether you are untangling standard financial ledgers or engineering a massive Life Sciences Insights Platform to process daily genomic workflows, this reality makes spec-driven delivery structurally wrong. It forces engineers to build against assumptions rather than reality, leading to brittle architectures that collapse in production.
Conversely, embedded engineering is structurally right. Databricks is uniquely powerful for unifying batch and streaming workflows, but maximizing that capability requires constant micro-adjustments. Following an evolutionary architecture model, our FDEs adapt the data models dynamically as new constraints emerge. This approach aligns the engineering effort directly with business reality.
To understand how this functions in reality, consider a recent cloud-first data modernization project handled by Opinov8. The client was operating a legacy Delphi-based risk calculation system. It was monolithic, incapable of scaling, and completely walled off from modern AI and BI tooling.
Worse, the system was a compliance liability in a highly regulated financial environment. A standard consulting engagement would have attempted to document the entire Delphi codebase before writing a single line of modern code. Instead, our FDE team embedded directly with their risk analysts to understand the actual mathematical outcomes required.
The team rapidly architected a cloud-first rebuild utilizing Databricks and Apache Spark. Every technical decision was framed by the embedded engineers working in-context, discarding legacy assumptions as their understanding deepened.
Because the FDE team owned the outcome, they implemented an architecture that prioritized future flexibility over rigid parity with the old system. They established the following core 2026 workflows:
The embedded model yielded results that a standard spec-handoff never could have achieved. The most immediate impact was scalability. The new platform easily handled larger, more diverse datasets, tearing down the computational bottlenecks that plagued the legacy system. We apply this exact methodology when building large-scale sensor ingestion pipelines for Maritime Intelligence and fleet analytics, where scale is a baseline requirement, not an upgrade.
Deployment velocity skyrocketed. By treating developer velocity as a core business metric, the automated CI/CD pipelines allowed the client to push updates daily rather than quarterly.
Most importantly, the data was finally ready to power actual intelligence. By properly structuring the Gold tables, the client could immediately use the clean data to power Enterprise RAG (Retrieval-Augmented Generation) applications and autonomous agentic workflows directly within the Databricks Data Intelligence Platform. This is identical to the underlying architecture we deploy to unify Commercial Real Estate (CRE) Operations with enterprise AI.
As global regulatory scrutiny intensifies, generic security is insufficient. Our FDEs delivered a compliant-by-design architecture. Operating from strategic European tech hubs like Lisbon, the team ensured that strict data segregation natively satisfied complex frameworks like the GDPR and the EU AI Act directly within the infrastructure code from day one.
Honesty is a requirement in technical consulting. The Forward Deployed Engineering model is incredibly effective, but it is not necessary for every single IT initiative.
If you are executing a simple, well-understood lift-and-shift server migration, you do not need FDEs. A fixed-scope project with zero ambiguity and strict, unchanging parameters is better suited for a traditional managed service contract. There is no need to deploy elite problem-solvers for tasks that can be fully automated or heavily scripted.
However, the FDE model shines brightest when the work is highly ambiguous and heavily dependent on domain knowledge. If the target state is evolving, or if you are completely untangling legacy constraints like a Logistics Operations Platform Modernization, standard delivery will fail you. If you are building agentic systems or deploying complex models at scale, you need engineers who own the outcome.
Ultimately, technology is just a toolset. The most advanced cloud data platform in the world will not save a structurally flawed delivery pipeline. What matters is the proximity of the engineers to the actual business problem.
When you embed the builders directly into the context of the operators, friction disappears. We do not just hand over a repository; we hand over a functioning capability.
As a validated leader ranked 6th out of over 7,377 firms on the Clutch Leader Matrix for AI Consultants, we know exactly what it takes to convert complex datasets into enterprise intelligence. If your data modernization is stalling, or if you need to maximize your Databricks investment without waiting for a six-month spec phase, connect with an official Databricks Consulting Partner. Let's talk about the problems you are actually trying to solve.